vivo AI计算平台弹性分布式训练的探索和实践
背景
2018年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设AI计算平台。经过两年的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化能力。VTraining是一站式的通用训练平台,支持多种框架的大规模分布式训练,并配备PB级别规模的分布式存储。现在VTraining已经有一定数量级的用户,来自人工智能、影像、互联网等多个部门;落地的业务众多,支撑着广告、语音、视觉、NLP等核心业务模型训练的迭代。本文分享了vivo AI计算平台在Kubernetes集群进行弹性分布式训练的实践心得。
弹性分布式训练的意义
在谈及弹性分布式训练之前,熟悉大数据作业的同学也许对MapReduce/Spark中的弹性作业有所了解。MapReduce/Spark支持可伸缩执行器(Scalable Executors)和测度执行(Speculative Execution)特性,使得大数据任务在运行过程中能够随集群作业的资源状况及节点的健康状态和运行性能来对任务job的分片进行弹性调度。类似于大数据任务中的弹性作业,弹性分布式训练旨在提供任务运行期动态调整任务资源的能力。弹性分布式训练可以解决以下几个痛点:
痛点1:任务容错性
随着集群规模的扩大,集群中给定时刻出现任意一台机器故障的概率也在增加,当出现节点临时故障的问题,缺乏容错机制的训练任务往往只能自认倒霉、重头再来。在深度学习的训练中,根据训练数据的量级和算力规模大小,一个epoch有可能耗时几小时甚至一天,即便用户训练代码有一定的容错意识为训练提供了checkpoint,出于性能考量,checkpoint无法设置太频繁,用户只能接受最近训练结果丢失的事实,并承受重新进行任务调度的时间成本,模型的迭代周期有变长的风险。弹性任务在运行时解决容错问题,单节点的失败不会影响整体训练。
痛点2:集群资源利用率
没有弹性能力的训练任务由于无法感知实时的集群资源状况,用户提交任务时只能事先确定好集群空闲资源,并根据这个信息来为任务分配固定算力。这意味着在集群资源出现空闲算力的情况下,如果没有新的任务提交,这些算力将一直闲置,即便用户的训练有利用更多算力提高模型训练效率的可能性,也需要用户自发重启任务进行重新调度。另一方面,由于一开始分配了固定算力,对于某些呈现多阶段不同资源使用pattern的任务来说,用户的任务有可能在某一环节长时间处于资源利用率低下的情况,这种情况由于不能回收资源,实际上空闲的资源也无法被再利用。弹性任务和调度系统配合能有效检测到这些潜在能被利用的资源,进而提升集群整体资源利用率。
痛点3:集群资源配置的灵活性
在k8s集群管理过程中,经常需要对机器进行运维管理,将机器划分为不同的用途供不同的业务使用。这种场景在离在线混部实践中出现的非常频繁。如果变更了机器用途,在不撤掉原有已调度的离线任务的情况下,考虑到机器内空闲资源和系统稳定性等因素,机器将不能100%地投入新的业务用途中。离线任务往往由于优先级不如在线任务,只能被折衷杀死。而弹性任务天然具有容错性,任务在不同用途的机器间进行漂移是支持的。
基于k8s的弹性分布式训练的实现难点
尽管在离线系统弹性任务的概念一直存在,可是由于各种原因在k8s上进行深度学习任务的弹性训练没有大规模应用开来。
难点1:训练框架与调度系统打通,实现弹性感知
MapReduce/Spark + Yarn是大数据领域的标准方案,由于执行框架上原生支持,弹性任务对于用户来说就如同呼吸一样自然,用户只需要按照MapReduce/Spark规范编写程序就可以获得弹性能力。但深度学习领域框架百花齐放,而且大部分框架也不会预设用户将训练任务部署在何种执行环境以及何种调度系统上。在各个框架上实现弹性控制的模块,以及进行对应调度系统的适配来实现弹性训练,这一工作量将非常大。即便不同框架都推出了自己的弹性训练方案,平台层面要整合众多框架的方案也有很高的维护成本。我们希望能以一种维护成本相对较低的方式支持尽可能多个框架的弹性训练。
难点2:训练容错支持不完善
现代深度学习模型训练方式基本上都是基于数据并行的,Parameter Server方式的数据并行在异步训练时由于训练算法的数学特性,天然具有容错性,任意worker失败只需要重启后加入训练即可,然而异步训练只有引入延迟补偿机制才能比较好地保持模型训练的收敛性和效果;另外,Tensorflow关于Parameter Server训练方式的实现上,利用tf.train.MonitoredTrainingSession实际上也可以为同步或异步提供基于checkpoint的容错机制,只是这种方式中当Chief Worker节点被挂起,任务依然只能通过重启恢复;对于基于RingAllReduce的同步训练情况,框架层面能提供的错误容忍也很有限, 比如Pytorch DDP在不依赖TorchElastic情况下当worker挂起会导致nccl hang。
考虑到要在所有框架上支持所有训练模式的容错训练非常困难,而且目前平台业务中深度学习模型更多采用的是RingAllReduce的训练方式, 我们在实践中暂时先支持RingAllReduce同步训练的容错。
弹性分布式训练实现方案
在k8s集群中部署机器学习训练任务比较主流的方案是使用kubeflow,平台在实践过程中经过调研,发现kubeflow中的tf-operator项目具有极高通用性和灵活性,能适配支持多种不同类型训练任务的生命周期管理,比如原生支持基于Tensorflow的ParameterServer的训练,简单适配还可以支持Pytorch Distributed DataParallel任务、Kaldi任务、MPI任务和XGBoost任务等,完全满足训练平台支撑多种业务多框架训练的要求。也正是这种前提条件下,训练平台重度依赖了tf-operator组件。
目前tf-operator社区暂时没有支持弹性训练任务的打算, 用户需要弹性训练就需要修改tf-operator的实现,或者在站在更高的维度实现controller尝试利用tf-operator的机制来支持任务算力的弹性调控。
事实上社区针对这个问题也进行过讨论(https://github.com/kubeflow/tf-operator/issues/708),从最终的结论来看tf-operator开发者也更倾向于从上层来建立弹性的机制。
出于可维护性和灵活性考虑,我们选择第二种方式。
tf-opeator的工作原理
tf-operator由于从一开始就是为Tensorflow 作业服务,在管理作业的生命周期时主要考量了Tensorflow ParameterServer的训练模式,pod被划分为三种角色类型Chief/Master、Parameter Server以及Worker。Chief/Master一般是统筹整个作业健康状态的角色,比如Ingraph Replication中的Client以及Tensorflow2.x中的ClusterCoordinator; Parameter Server是专门用于存放参数分片的一组服务节点;Worker是训练中负责计算并同步参数的节点。当Chief/Master角色不存在时甚至连Parameter Server也不存在时,Worker中的0号节点将充当ChiefWorker,对应Between Graph Replication中使用MonitoredSession指定Worker0为Chief或在Worker0启动MPI-based RingAllReduce训练的场景。
tf-operator在管理过程中会根据训练模式中不同角色的约定及特性来决定作业的状态,当节点被挂起后根据节点角色的语义判断是否需要重新创建。
以下是tf-operator的基本工作流程图:
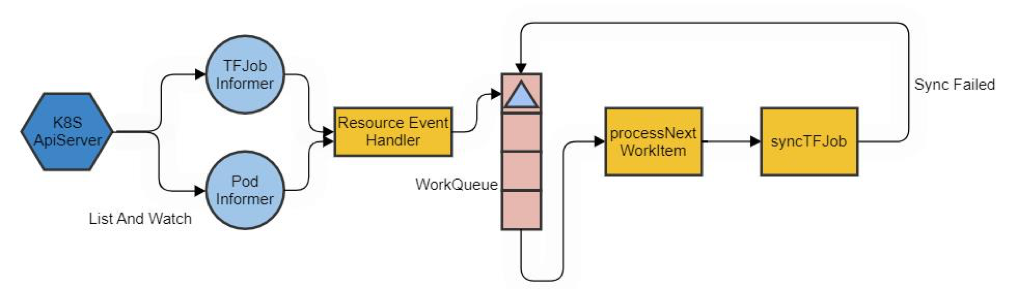
其中,syncTFJob是tf-operator管理对象的核心逻辑实现,内部对不同ReplicaType的Pod进行检查并推导出任务状态,逻辑流程图如下:
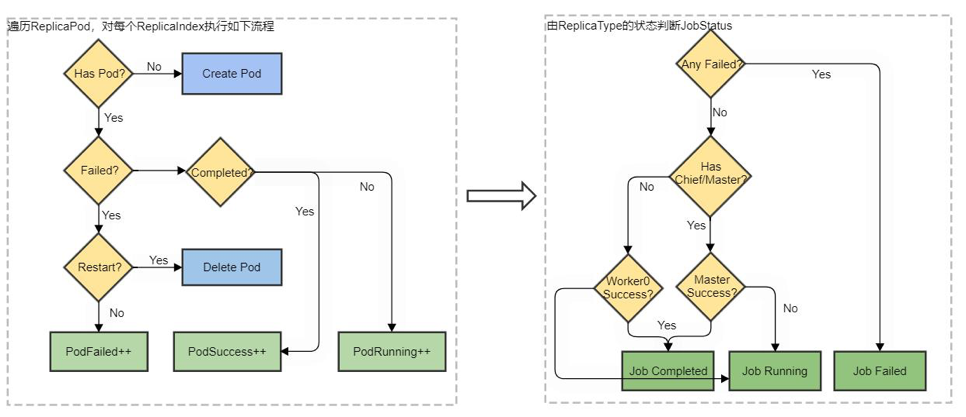
根据上边的流程图可知,当作业中既有Chief又有Worker时,正常情况下Chief的状态决定了整个作业的状态,当有Worker被驱逐时operator会根据当前TFJob配置中的Replicas的数值来确认是否需要创建新Pod。这意味着我们可以在上层通过设置TFJob的对应ReplicaType的Replicas数值以及调用k8s api驱逐pod来实现作业伸缩。
利用tf-operator实现作业的hpa/vpa
根据上边介绍tf-operator的工作原理,我们可以标准化弹性作业的角色,为每个弹性作业配备一个Chief来负责作业容错以及弹性算力感知的工作,并在PS(如果有的话)或Worker上建立容错机制来实现弹性训练。基于这一前提,我们实现了一个提供ScaleJob接口的作业管理服务来接收来自其他组件的作业伸缩请求,底层利用operator本身维护TFJob状态并重建Worker的机制来实现作业的横向伸缩,甚至纵向伸缩。
以横向伸缩为例,当需要扩张Worker时,修改TFJob的Worker Type的Replicas至更大数值,tf-operator便会自动创建Worker Pod; 当需要收缩Worker时,修改TFJob的Worker Type的Replicas至更小数值, 并调用Evict/Delete api驱逐多余的Pod。同时为了保证gang-scheduler的调度机制(如抢占逻辑)正常进行,以及考虑到job的voluntary disruptions策略,伸缩需要维护PodDisruptionBudget对象,将minAvailable调至合适数值。
具体操作流程图如下所示:
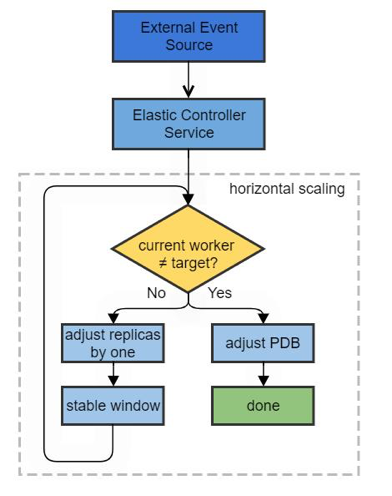
上边的stable window是一个训练worker状态变化开始的不稳定状态逐步到稳定状态的过渡时间窗口,包含了worker重新创建或销毁的时间。
实现的时候考虑到不同任务effective training batch对训练的影响,我们为TFJob对象指定Annotation来标明每个任务支持的Worker数量范围,调整replicas数量和pdb minAvailable数值时会考虑这个信息。
作业的垂直伸缩可以一种取巧的方式实现,即通过横向伸缩的方式使用新资源配比的worker逐台替换掉老的worker,流程如下:
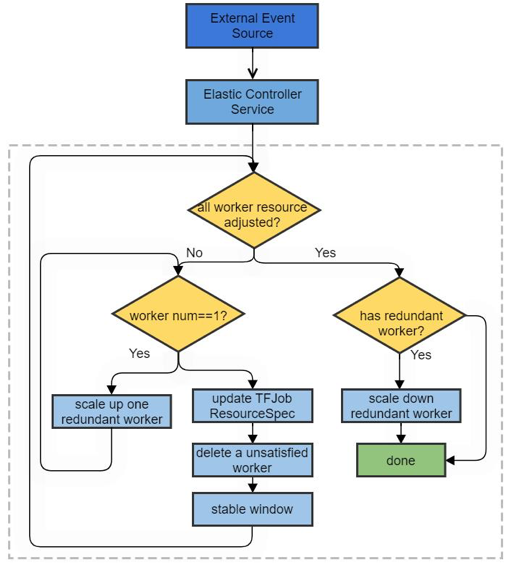
这个过程中通过更新TFJob 中的Worker的ResourceSpec,再删除老worker并由tf-operator重新创建具有最新资源配置的新worker,视感上可以得到作业的pod资源垂直伸缩的效果。特别地,当原来作业资源只有一个时,考虑到深度学习任务中的参数在线同步,需要先带起一个新worker来获得参数的副本,再等垂直伸缩完成后删除这个备份的副本。
容错性及弹性算力感知
在平台的大部分训练业务中,深度学习的模型训练上主要采用了horovod来进行RingAllReduce训练,为此我们利用了horovod在0.20版本以上支持的elastic功能;另外语音识别业务由于技术选型上重度依赖kaldi框架,而kaldi的负载分发引擎不支持k8s,开源社区也并没有支持的打算,我们自研了基于k8s的负载分发框架,并支持类似Sun Grid Engine体验的弹性伸缩。
horovod 弹性支持
horovod 0.20之前的版本使用了mpi collective通信原语来实现整个RingAllReduce过程的controller,0.20之后的版本考虑到弹性算力感知的需要使用了gloo的通信库来实现controller以便能动态修改通信的world_size以及调整每个训练Worker的rank。
horovod elastic的工作原理如下图:
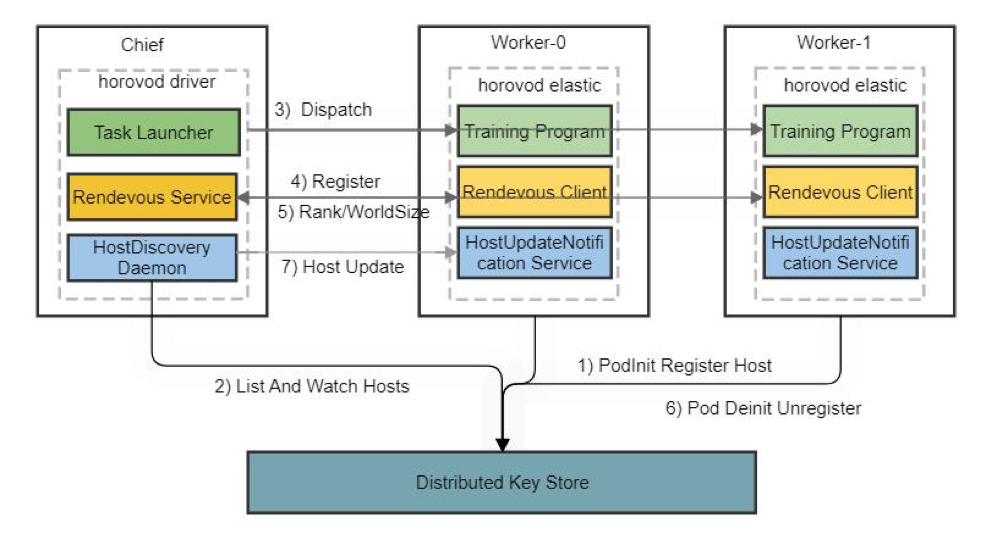
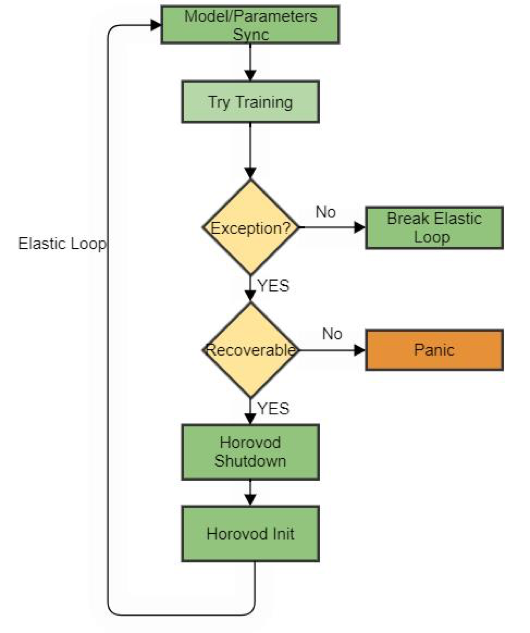
其中每个Worker在driver下发训练后都将进入elastic 循环,用户训练代码也包裹其中,如下图:
一开始作业启动时,horovod driver(horovodrun程序)从HostDiscovery接口或根据静态指定的Static Host选项中获取到可以用于本次作业的算力(k8s中的Pod),只要此时允许调度的working slot的数量大于允许数量,driver就往对应working slots上分发训练程序;分发的elastic 训练程序在对应的slot启动后便向driver汇报,并获取本次训练的WorldSize以及自己slot的Rank和LocalRank等, 这个过程称为集会(rendezvous)。
当训练节点需要被驱逐时,horovod引入了三种容错机制,一是driver通过HostDiscovery检测到Worker数发生变化,通知各Worker发生了HostUpdate;二是为gloo operations指定超时来为controller进行通信时进行容错; 三是通过在horovod的elastic loop中捕捉Boardcast、AllReduce及AllGather等异常。这样当错误检测发生时,所有worker会重回集会过程,等待算力满足条件后再重新开始训练;为了减少因为重新训练而重复进行的训练步数,horovod提供了api允许用户在elastic loop中每隔若干个steps进行一次commit操作来保存梯度,并且当集会结束后进行一次Boardcast来同步梯度和超参数。
当有新的训练节点加入时,driver 从HostDiscovery接口探知到新增的slots,给现存的Rank0的节点发送HostUpdate消息,Rank0的训练程序接收到消息后将进行horovod shutdown,导致所有的worker重新进入集会;同时driver往新增的slots 下发训练程序,所有slot的训练程序完成集会及信息同步后会继续训练。
在节点驱逐场景,horovod elastic原生实现存在一些缺陷,一是当节点失败后,无论是驱逐还是节点崩溃,都认为节点无法恢复,这在k8s集群中显然是不合理的,因为tf-operator在可能的情况下总是会重建同名的新worker;二是在GPU训练场景,当指定HOROVOD_GPU_OPERATIONS为nccl时,nccl由于通信过程在cuda kernel内部,peer节点被驱逐时有可能导致算子中断引发hang或coredump现象,此时错误并不能被优雅捕捉到,导致整个作业失败。针对这两个问题,平台对官方的horovod进行了改造,第一个问题修改了horovod driver代码,为失败blacklist的节点增加了重试机制,并向官方提交了pr(https://github.com/horovod/horovod/pull/2483); 问题二中,我们引入了一种基于SigUSR1信号的优雅退出机制,在elastic loop中捕捉该信号,并通知horovod shutdown来消耗已经入队的梯度操作,同时切断gloo通信来触发gloo operations timeout来通知其它peer。
另外,horovod的HostDiscovery接口实际上是通过执行脚本的形式来实现的,horovod根据脚本的执行结果知道当前可以进行训练的slot信息。实践过程中,平台为弹性作业的pod添加PreStart/PostStop生命周期的钩子,当有新pod启动时往分布式存储写入一个key,pod销毁时注销这个key。HostDiscovery脚本在执行过程中动态检查pod key的集合,并根据pod的申请资源的情况决定可以执行训练的slot的数量。
kaldi 弹性支持
语音识别的kaldi提特征、解码等cpu型任务,具有和大数据作业类似的属性,任务中一个executor重启不会影响整体,只要任务一开始切分好需要处理的数据,同一任务内不同的作业之间都是相对独立的。所以只要使用的作业分发框架支持对作业失败状态的捕捉就可以实现容错;另外,只要将数据切分得足够多份,当新增弹性算力时,负载分发框架感知到这种变化后可以将pending的作业调度到新增加的slot中。
负载分发框架对算力的感知同样也依赖我们对pod生命周期的钩子。
kaldi elastic负载分发框架工作原理如下图:
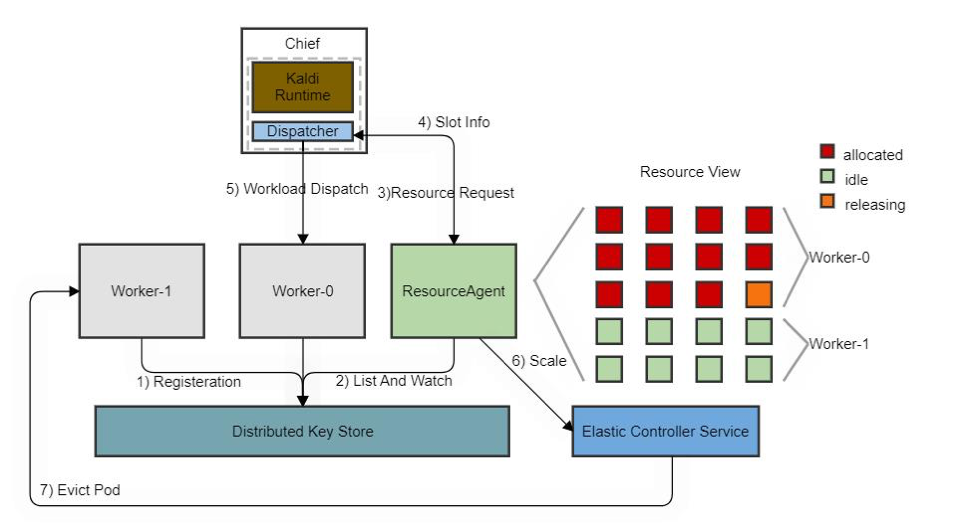
可以看出,作业容器的资源会由ResourceAgent监听分布式存储中作业的pod对应的key,统一管理并编排成slots的形式,当kaldi driver程序发送计算调度请求时会由ResourceAgent查找当前容器来空闲的slot,并为执行进程绑定slot信息;当空闲slot不足时,会主动请求controller申请扩容;当slot长时间空闲时,会请求controller回收对应的pod。
保障性措施
基于上述方案的弹性分布式训练,依然有一个漏洞,Chief节点对作业来说属于Critical节点,当Chief节点被驱逐或节点失败时,作业会重启或失败。为了要保证Chief的可用性,我们可以为Chief节点指定nodeSelector,指定专用的非弹性用途的节点用于调度;另外由于Chief节点负载非常低,这类专用节点一般是稳定的。
总结展望
弹性分布式训练可以大大提高集群资源利用率以及资源配置的灵活性,vivo AI计算平台建立了初步的弹性分布式训练机制,支持深度学习基于RingAllReduce的弹性训练和语音Kaldi识别任务的弹性作业。未来平台还将支持ParameterServer的弹性算力感知,逐步打通与如利用率监控和离在线混部资源管理等资源调控组件的关节,不断完善弹性分布式训练的基础设施。
vivo AI计算平台相关文章
vivo AI 计算平台 Kubernetes 集群 Ingress 网关实践
作者介绍:
林国泽,曾就职于商汤科技,目前是vivo AI研究院计算平台组的资深工程师,关注领域包括机器学习系统、高性能计算、云原生技术等。